AI 配音的技术本质与现状
AI 配音是通过神经网络模拟人类发声器官的共振与情感起伏,将文字转换为具有人类特征声音的技术。到 2026 年 3 月,该技术已从简单的“文字转语音”进化到能实时渲染呼吸感、语气停顿及情感共鸣的阶段。
目前 AI 配音处于技术飞跃与感官容忍度降低的矛盾期。2025 年底《香蕉鱼》AI 配音版本的争议证明,即便实现了高精度的声音克隆,若缺乏对剧作节奏的理解,成品依然会显得乏味。这表明配音的本质是情感传递,而非单纯的声音模拟。
核心技术架构:从频谱到波形
技术底层采用端到端(End-to-End)架构。
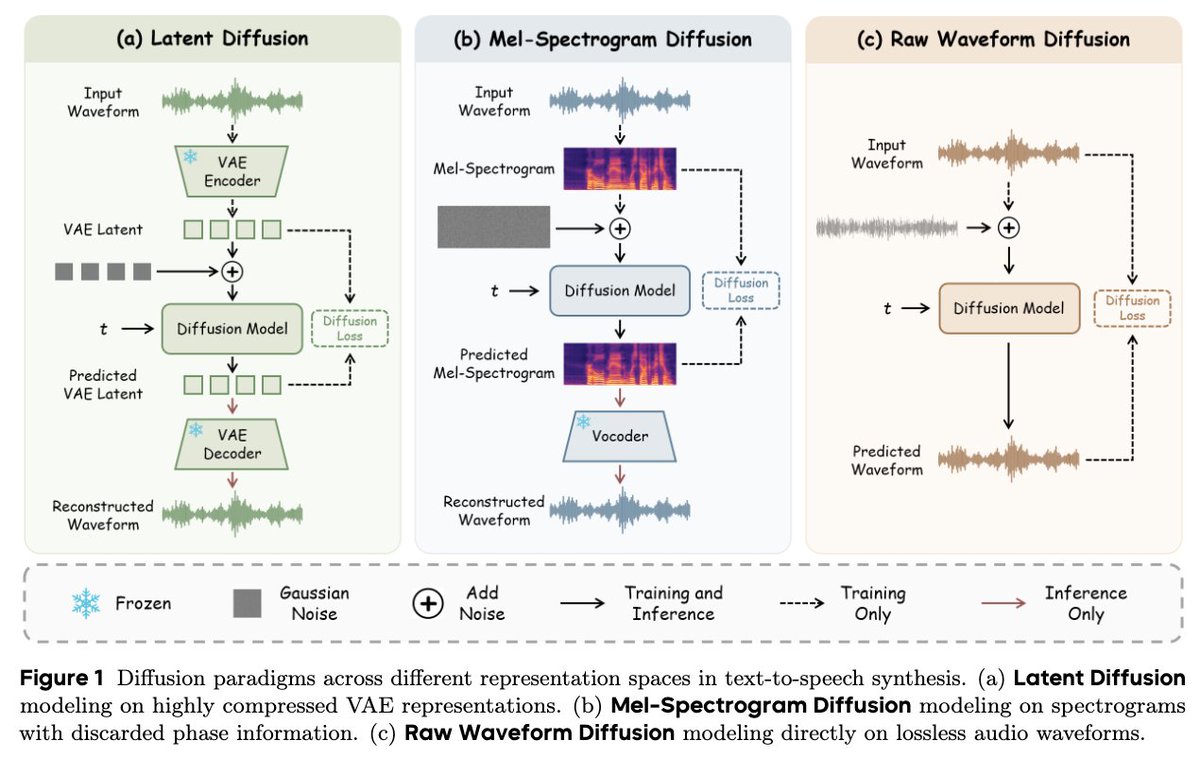
主流方案由“声学模型 + 声码器”组成:Transformer 等架构的声学模型先将文字转为梅尔频谱图(Mel-spectrogram),记录频率随时间的变化;随后由 HiFi-GAN 等声码器将频谱图还原为波形音频。为了提升自然感,模型引入了情感向量(Emotion Embedding),允许用户调节“悲伤度”或“兴奋度”。此外,利用少样本学习(Few-shot Learning),仅需 30 秒真实人声采样即可克隆出极具辨识度的音色。
主流 AI 配音工具的功能分化
市场工具已出现明显的功能分化。

不同的平台在情感表现、并发能力和延迟响应上各有侧重,具体对比见下表:
| 工具名称 | 核心优势 | 适用场景 | 局限性 |
|---|---|---|---|
| ElevenLabs | 情感一致性、多语言克隆 | 叙事短片、有声书 | 商业授权费用较高 |
| Azure / Google Cloud | 工业级稳定性、海量并发 | 智能客服、系统播报 | 灵动感与情感起伏不足 |
| OpenAI Voice Engine | 极低延迟、实时响应 | AI 助手、实时翻译 | 定制化精细调控较少 |
| GPT-SoVITS (开源) | 极致音色克隆、免费 | 个人创作、特定角色还原 | 需高配 GPU,部署复杂 |
高质量 AI 配音的“半自动”制作流程
想要获得高质量 AI 配音,建议采取“半自动”精细化流程,而非直接生成:
AI 配音的局限性与实操建议
AI 配音并非万能。在处理“极高情感张力”场景(如撕心裂肺的哭戏)时,AI 只能模拟声音形式而无法模拟“克制中的悲伤”,易产生违和感。对于追求独特断句、不标准发音的个人风格化表演,AI 追求统计学正确性的逻辑会导致角色平庸。
Q: 开源模型和 SaaS 平台该如何选择?
建议从价格、效果、风险和场景四个维度考量。开源模型(如 GPT-SoVITS)成本低且克隆精度高,但需硬件支持;SaaS 平台适配稳、速度快,但按字符收费且缺乏深层定制。短视频适合 AI,而 3A 游戏主线仍需顶级声优。
Q: 如何在预算有限的情况下保证配音质感?
建议将 AI 定位为“高效素材生成器”。采用人机协作模式:用 AI 生成 80% 的基础对白,针对 20% 的核心情感转折点聘请专业配音员,最后通过混音融合。这种模式是在成本可控的前提下,保留作品灵魂的最优解。