AI 视频生成的底层逻辑:从像素合成到物理模拟
AI 视频生成已从简单的片段合成进化为具备物理模拟能力的生产力工具。目前的行业分水岭在于:通用大模型(如 Sora 2、Kling 2.6、Wan 2.6)主攻视觉冲击力与长视频生成;而精准控制工具(如 Seed Edit)则侧重于局部修改。对于创作者而言,核心痛点已从“能否生成”转移到“如何消除合成感”以及“如何控制商业交付预算”。
AI 视频能够驱动动态效果,依赖于 DiT(Diffusion Transformer)架构。
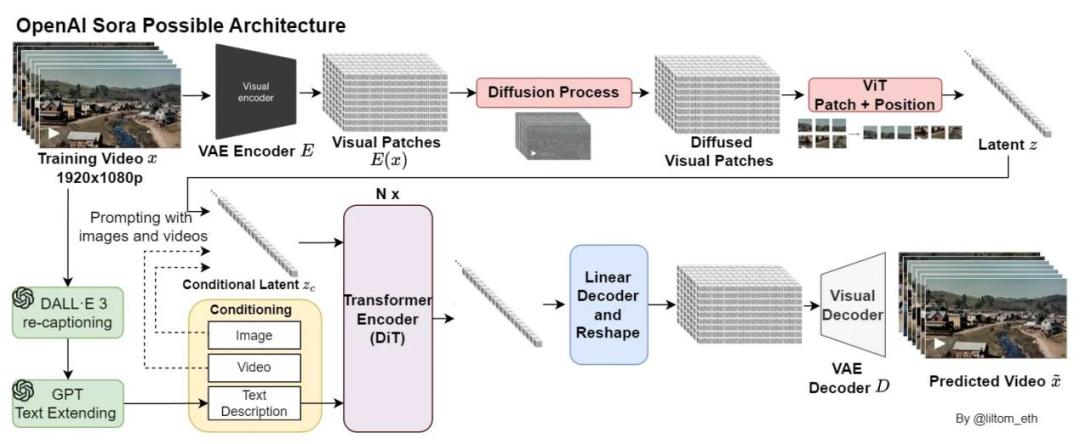
该架构将视频拆分为三维的“时空补丁”(Spacetime Patches),在潜空间中通过预测并去除噪声,将随机像素引导至符合文本描述的状态。2026 年的技术突破在于引入了物理引擎先验,使得物体破碎、液体流动等动态效果开始符合重力规律,解决了早期版本中常见的物体漂浮或异常融化问题。
提升视频质量的“分层构建法”与实操技巧
高质量视频不能依赖单一提示词,建议采用“分层构建法”。先用图像模型生成基准图(Keyframe),再将其输入视频模型,并配合运动笔刷或摄像机路径控制。这种链路能显著降低随机性,防止角色在镜头切换时出现面部特征漂移(跳脸)。
以 Kling 2.6 的实际操作为例,可将生成成功率最大化
通过 Midjourney 或 Flux 生成符合要求的人物肖像并上传至 Image-to-Video 界面。在提示词中仅描述动作(例如“女孩在雨中街道快速奔跑,镜头侧面跟拍,水花在脚下溅起”),避免在提示词中重复描述外貌,以维持角色一致性。
将运动强度参数设定在 4-6 之间(高于 8 易导致形变,低于 3 则过于静止)。同时开启“高画质模式”消除背景噪点,并将帧率设定为 30fps 以解决视觉卡顿。
最后,处理物理崩坏。
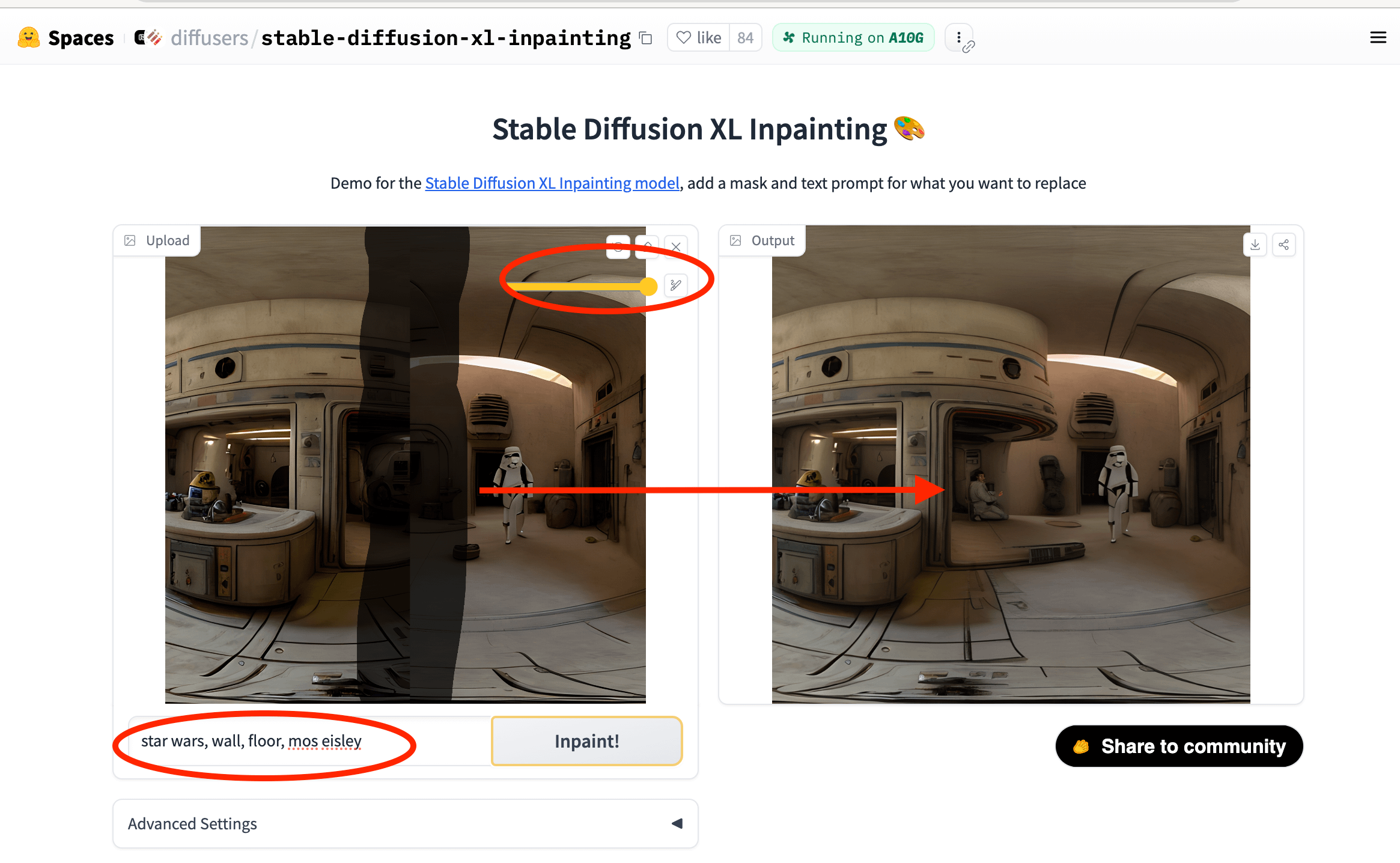
若出现衣服穿透身体等错误,无需全部重来,可使用局部重绘(Inpainting)功能,用掩码覆盖出错区域并输入“自然下垂的手臂”进行迭代修正,以节省算力额度。
技术边界与商业成本分析
即便技术迭代迅速,AI 视频仍存在明确的边界。首先是高频运动中的文字渲染,招牌或文字在快速移动时仍易扭曲。其次是超长距离的逻辑一致性,维持角色在 10 分钟视频中的服装细节完全一致,依然依赖大量人工干预。
特定场景目前不建议使用 AI 生成:一是极高精度的工业产品展示,如手表齿轮的精密咬合;二是细腻的面部微表情,处理“欲言又止”等复杂情绪时仍有“恐怖谷效应”。
商业成本方面,定价模型已从包月制转向“算力点数”机制。独立制作者在接单时需预留足够的试错成本,因为无法保证短时间内生成客户满意的最终版本。
不同生成路径对比表
| 生成路径 | 成本/算力 | 可控性 | 适用场景 |
|---|---|---|---|
| 纯文本生成 | 低 | 低 | 灵感寻找、低成本短视频 |
| 图生视频 | 中 | 高 | 商业广告、短剧 |
| 视频重绘/编辑 | 高 | 极高 | 特效补拍、风格迁移 |
未来趋势:从单一模型转向混合工作流
AI 抹平了技术操作门槛,但拉高了审美和导演思维的要求。缺乏蒙太奇和构图基础的创作者,生成的视频仅是碎片化的视觉奇观,缺乏叙事力量。
目前的最高效路径是构建“混合工作流”。
具体链路为:Flux 生成素材 $\rightarrow$ Kling 2.6 赋予动态 $\rightarrow$ Topaz AI 超分辨率增强 $\rightarrow$ 剪辑软件手动补帧。建议初学者先利用免费额度跑通该链路,确认视觉风格在模型能力范围内后,再投入算力成本。
如何有效避免 AI 视频中的“跳脸”现象?
最有效的方法是采用“图生视频”而非“文生视频”。通过提供一张高质量的基准参考图,锁定角色的面部特征,并在视频提示词中仅描述动作,尽量减少对外观的重复描述,从而维持角色在不同镜头间的一致性。
运动强度参数设置过高会有什么影响?
当运动强度参数(如 Kling 中的 Motion 强度)过高(通常 > 8)时,模型为了追求大幅度动作,容易在预测像素时产生逻辑错误,导致肢体重叠、物体形变或背景剧烈扭曲。
目前 AI 视频是否可以完全替代实拍?
在氛围感短片和概念展示中可以替代,但在极高精度的工业产品展示和细腻的情绪微表情捕捉上,AI 仍存在“恐怖谷效应”或物理偏差,目前最理想的状态是 AI 生成与实拍素材的有机结合。