AI 视频生成正从“视觉奇观”转向“生产工具”。其核心是通过扩散模型(Diffusion Models)或 Transformer 架构,将文本、图像指令转化为动态画面。预计到 2026 年 3 月,行业将突破单纯的“画面闪烁”阶段,实现对镜头语言、光影逻辑及长时长连贯性的精准控制。
目前 AI 视频的矛盾点在于:视觉质量已达商业级,但精准控制(如视频版 ControlNet)仍与模型的随机采样之间存在拉锯。对于专业创作者,不可控的随机性是最大的痛点。
核心原理解析:从噪声到画面的演进
主流方案基于潜空间扩散模型(Latent Diffusion Models)。模型在训练时学习将清晰图片逐步转化为随机噪声,生成时则执行逆向操作:在噪声中识别符合文本描述的模式,通过数千次迭代去噪还原图像。
视频生成的难点是“时间维度的一致性”。若每帧独立生成,画面会出现剧烈抖动。尖端模型通过引入时间注意力机制(Temporal Attention),使模型在生成当前帧时参考前序帧的像素分布和运动矢量。这样在 24fps 的流畅度下,人物肢体轨迹、衣服褶皱和背景透视才能保持逻辑统一。
实操指南:使用 Creatify 生成电商转化视频
对于亚马逊或独立站卖家,手动剪辑成本较高。Creatify 采用“数据驱动生成”,通过抓取产品页面信息构建视频逻辑,减少了对复杂 Prompt 的依赖。
第一步:资产导入与解析
第二步:脚本优化与视觉匹配
第三步:参数配置与渲染
工具横向对比:专业级 vs 效率级

建议根据产出目的选择工具,而非追求全能。
| 维度 | 效率级 (如 Creatify, CapCut AI) | 专业级 (如 Sora, Kling, Veo) |
|---|---|---|
| 核心定位 | 快速出片,商业转化 | 极致画质,创意表达 |
| 成本模式 | 月订阅 (约 $20-50) | 时长计费或高额订阅 |
| 适用场景 | 电商短片、社媒铺量 | 广告创意片、电影预告 |
| 主要风险 | 视觉风格同质化 | 生成耗时长,版权模糊 |
版权与技术局限:专业人士的避坑指南
版权是目前最大的法律风险。以谷歌 Veo 为例,当创作者使用私有素材训练生成衍生作品时,平台协议可能在模糊地带主张部分所有权,或无法提供法律意义上的“纯净”版权证明。建议将 AI 视频作为“动态分镜(Animatic)”或背景元素,通过后期合成加入自有版权素材,构建法律防御屏障。
同时,以下场景暂不建议依赖 AI:
- 高精度人机交互:如手术器械操作、精密机械组装。AI 易在手指数量、零件衔接处出现“融化”现象。
- 细腻情绪递进:AI 能生成“哭泣”状态,但难以精准控制从“压抑”到“崩溃”的微表情转变。
- 强一致性长叙事:在 10 分钟以上的视频中,保持同一角色面相、服装完全一致(且不通过 Lora 训练)仍存在跳帧问题。
执行建议:从 Prompt 工程师转向视觉导演
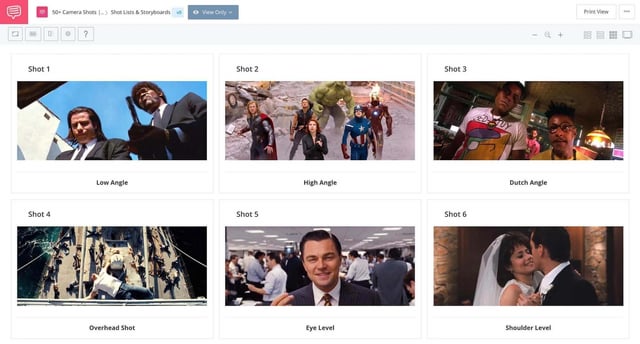
Prompt 的权重正在下降,视频语言的掌控力正在上升。建议学习基础电影镜头语言:推拉摇移、黄金分割构图、180 度轴线原则。当你能指定“低角度跟拍镜头,焦段 35mm,伦勃朗光”时,生成的视频才会具备商业价值,而非随机的数字幻梦。