AI 翻译的核心是将文本转化为高维向量,利用概率预测生成目标语言中可能性最高的表达。它已从简单的词典对译演变为基于上下文的语义重构。但这种底层逻辑决定了 AI 并不真正“理解”法律的严谨性或医学的绝对性,而是在生成一个看起来最像正确答案的句子。因此,在专业领域,AI 翻译容易产生“统计学幻觉”,导致关键信息的偏差。
目前的翻译竞争力已从准确率转向“可控性”。翻译链路通常分为基础机器翻译(NMT)、大模型生成(LLM-based)和人机协作(PE)。虽然 LLM 赋予了译文风格迁移的能力,但也引入了不可控的虚构风险。要确保专业文档的交付质量,必须构建一套高精度的翻译工作流。
第一步:构建动态术语库(Glossary)强制约束
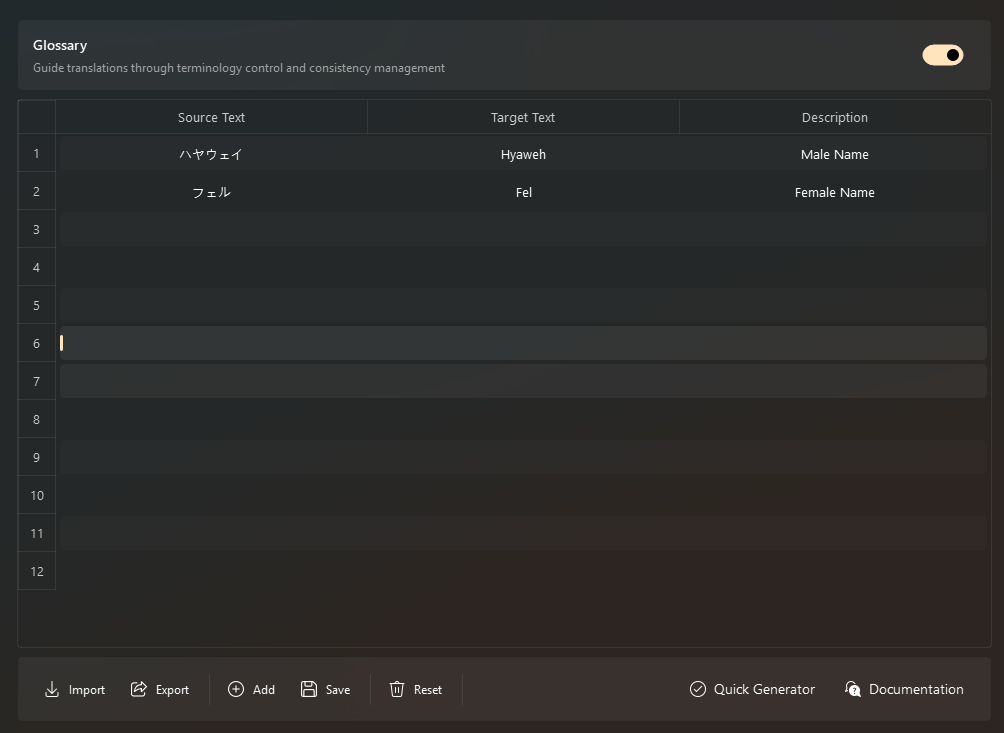
术语不统一是专业翻译最大的失误。若同一零件在同一文档中出现多种译名,将直接降低文档的可信度。解决此问题不能依赖 AI 的自觉,而应通过硬性约束实现。
1. 整理一份 CSV 格式术语表,包含:源语言词汇、目标语言标准译名、上下文定义(例如将 "Latency" 明确为 "延迟" 而非 "潜伏期")。
2. 使用支持术语库的工具(如 DeepL Pro 或在 GPT-4o 的 System Prompt 中定义)。
3. 在 Prompt 中加入指令:"请严格遵守术语表,禁止使用同义词替代,必须原样输出译名。"
针对 AI 为追求流畅度而篡改术语的问题,可增加负向约束:"不要为了语感修改专有名词"。这样能确保专业词汇 100% 一致,而将 AI 的自由发挥限制在连接词和语法结构上。
第二步:通过角色设定与上下文增强优化 Prompt
通用指令往往带来平庸的结果。高质量翻译需要为 AI 配置具体的身份和场景感知力。
采用结构化 Prompt 替代简单指令。配置包含四个维度:
1. 角色定义:定义为拥有 20 年经验的[具体领域]资深翻译,强调严谨性与流畅度的平衡。
2. 任务目标:明确文档类型(如:技术白皮书)和目标语言。
3. 风格约束:明确受众(如:行业专家),要求表达专业、克制,禁止使用感叹词或夸张形容词。
4. 迭代审查:要求 AI 先出初稿,再自检是否存在语义重复或不符合目标语习惯,最后输出终稿。
若中译英出现过重的“翻译腔”(如冗余的 Of 结构),可在 Prompt 中要求
"Use active voice where possible"第三步:利用比对工具验证语义漂移
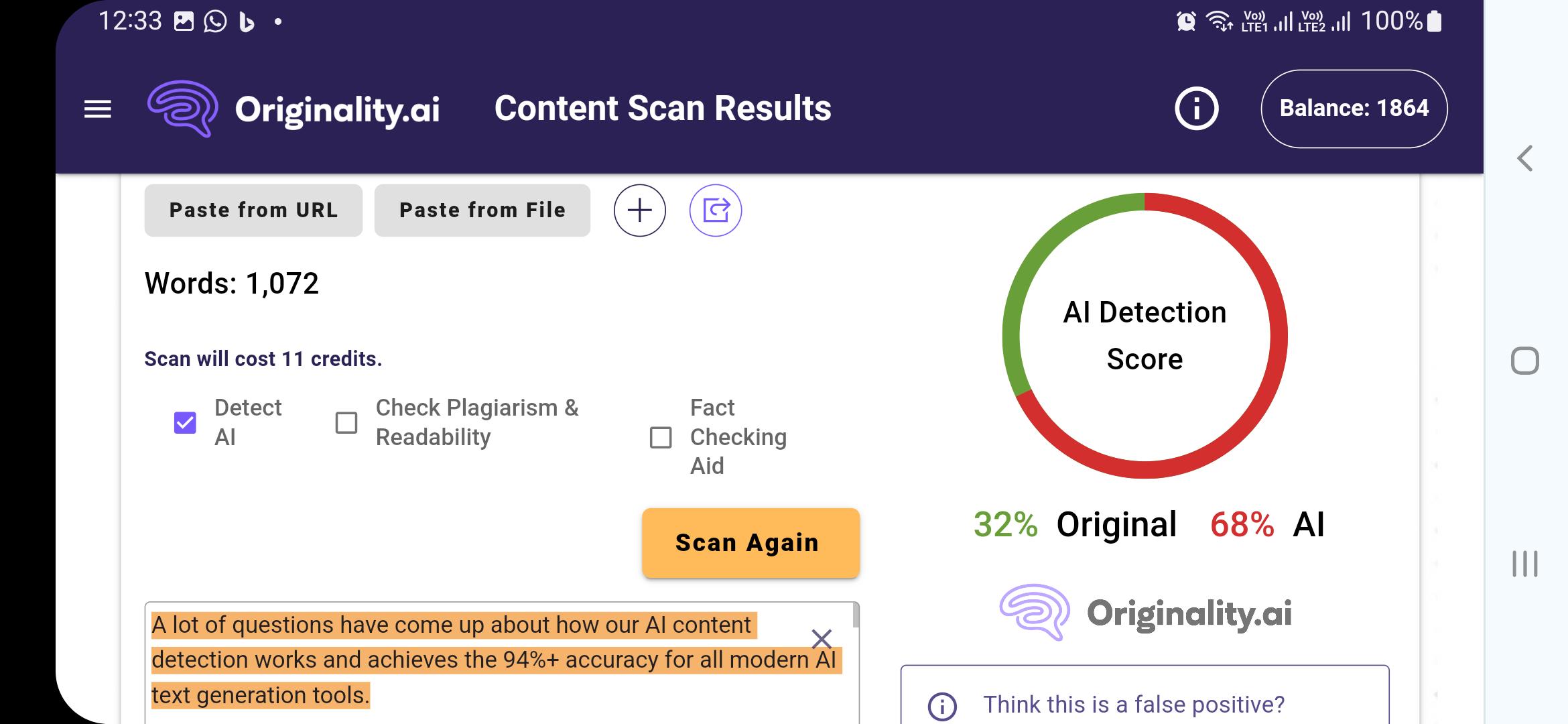
LLM 倾向于选择高概率表达,导致不同用户翻译同一段话的结果高度相似,在学术或商业报告中易产生“伪抄袭”风险。
将终稿导入 iThenticate 或 Plagscan,重点关注连续 7 个单词相同的片段。若重复率过高,说明表达过于模版化。此时可要求 AI:"In maintaining the exact technical meaning, paraphrase the following section to sound more natural and unique"。
为避免专业术语被误判为抄袭,应将术语表设为“忽略列表”。这样可确保文档既符合专业标准,又无明显的 AI 痕迹。
主流 AI 翻译方案对比

| 工具 | 核心优势 | 主要劣势 | 适用场景 |
|---|---|---|---|
| DeepL Pro | 句法流畅度高,处理长文稳定 | 冷门专业词汇处理较弱 | 商务邮件、通用行业报告 |
| GPT-4o / Claude 3.5 | 强理解力,可深度调整语气 | 易产生幻觉,可能增加冗余信息 | 营销文案、风格化文档 |
| Google Translate | 语种覆盖极其广泛 | 风格僵硬,学术感较弱 | 快速浏览、简单词汇查询 |
哪些场景不建议完全依赖 AI 翻译?
AI 在处理高度专业化或具有文化深度的文本时仍有局限。典型的风险场景包括: 法律合同(如 "Shall" 与 "Will" 的法律效力差异)、创意写作(文化隐喻与双关语的丢失)以及前沿学术论文(新概念尚未进入语料库,易被旧概念替代)。
如何彻底消除 AI 翻译中的“翻译腔”?
建议通过“结构化角色设定”赋予 AI 母语者身份,并明确要求其使用主动语态(Active Voice)或针对特定受众进行风格重写。最后,通过人工语义核验,剔除冗余的介词结构和机械的句式重复。
面对当前的翻译生态,建议构建“AI 初译 $\rightarrow$ 术语强制对齐 $\rightarrow$ 人工语义核验 $\rightarrow$ 查重工具校验”的闭环链路。这种流程虽然增加时间成本,但能确保专业交付的可靠性。