AI 绘画的底层逻辑:从随机生成到概率分布
AI 绘画本质上是通过深度学习模型,将文本描述或参考图转化为视觉图像的生成技术。其核心逻辑是预测像素排列的概率分布,而非人类意义上的“创作”。截至 2026 年 3 月,这项技术已从单纯的图像生成工具,演变为一种精准的“视觉语言编程”,深刻改变了商业设计与艺术定义的底层逻辑。
目前的 AI 绘画已告别随机生成的“抽卡”时代。从 2025 年底起,精准控制(Precise Control)取代了随机概率,成为衡量 AI 绘画能力的核心标准。如果你仍依赖简单的提示词等待运气,意味着你尚未触及这门技术的进化核心。
AI 绘画依托于潜空间(Latent Space)的数学映射。
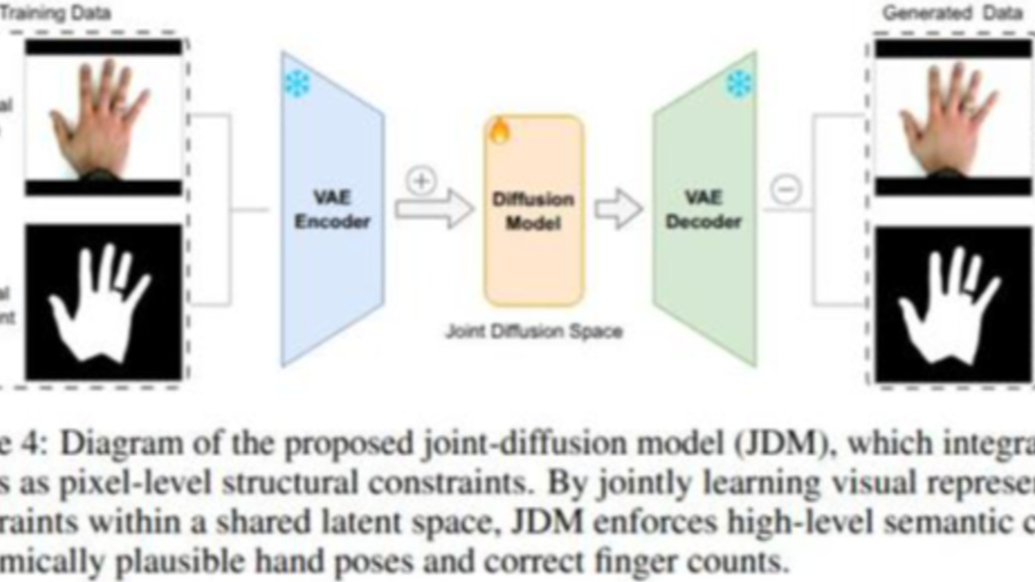
模型在训练阶段将数亿张图片及其描述映射至高维向量空间。当你输入“赛博朋克风格的上海”时,AI 并非在搜索并拼接图片,而是在潜空间中寻找两个概念向量的交集,随后通过扩散过程(Diffusion Process)将随机噪声图像逐步“去噪”,还原成符合概率分布的画面。这种机制决定了 AI 处理的是概率,而非理解美学。
专业级 AI 绘画精准控制工作流
掌控 AI 绘画需要构建一套完整的工作流。目前最高效的组合方案是:使用 Midjourney v7 快速迭代视觉方向,再利用 Stable Diffusion (SD) 实现像素级修改。
第一步:视觉原型的定向生成
此阶段的目标是获得构图与光影正确、但细节可能存在瑕疵的高分辨率原图。若出现图像崩坏,通常是提示词冲突,删除冗余修饰词、仅保留强视觉指向的名词即可解决。
第二步:基于 ControlNet 的结构化控制

这样 AI 会在维持原图线条结构的前提下,仅改变材质与光影。若线条断裂,可将 Ending Control Step 调高至 1.0。
第三步:利用 IP-Adapter 解决角色一致性
如果画面显得僵硬,通常是 IP-Adapter 权重过高,建议适当调低并增加“distorted face”等负向提示词。
第四步:高阶修复与超分辨率放大

低于 0.3 无法增加细节,高于 0.5 则会改变原图内容。通过分块渲染,AI 会自动补全皮肤纹理、织物纤维等微观细节。若出现重复图案(Tiling artifacts),请减小分块大小(Tile size)。
技术反思:审美力与定义力的回归
AI 绘画正在重复摄影术出现时的历史路径:它让执行力变得廉价,从而提升了“审美力”和“定义力”的价值。AI 冲击的并非艺术本身,而是低端商业执行的利润。缺乏个人风格、仅靠软件熟练度的画师面临危机,但对于创作者而言,AI 是捕捉潜意识镜像的高效画笔。
不同工具的选择逻辑取决于需求。
| 工具 | 核心优势 | 局限性 | 建议用途 |
|---|---|---|---|
| Midjourney | 氛围感强、快速迭代 | 黑盒化,精准控制弱 | 视觉定向、概念草图 |
| Stable Diffusion | 强插件生态、开源可控 | 硬件要求高,学习曲线陡 | 细节打磨、角色统一 |
| Photoshop | 传统合成、图层管理 | 非生成式,效率依赖人工 | 最终交付、精准合成 |
局限性分析与应用禁区
尽管技术飞跃,AI 绘画仍有明显局限。首先是逻辑真实性的缺失,即便 2026 年的模型在肢体处理上有所进步,但在复杂机械结构、特定透视关系上仍易出错。其次是“意图漂移”,AI 只能拟合概率标签而无法理解情感。要求它画出“深刻的孤独感”,它会给出蓝色调或窗边看雨的图,因为这是数据集中的视觉标签,无法替代基于生命体验的真实表达。
在以下场景中,不建议依赖 AI 绘画:
- 精度极高的工业设计图: 因其生成的尺寸缺乏物理意义。
- 需要绝对原创法律保障的顶级商业 Logo: 因版权法目前仍处于模糊地带。
- 快速草图沟通: 此时手绘效率远高于编写提示词。
AI 绘画会完全取代画师吗?
它取代的是“执行力”而非“创造力”。低端商业执行的利润会被摊薄,但能够定义视觉标准、拥有个人风格并能驾驭工作流的创作者,其价值将通过 AI 的放大效应进一步提升。
新手应该从哪个工具入手?
建议先从 Midjourney 开始培养审美和方向感,待对视觉构成有一定掌控后,再转向 Stable Diffusion 学习 ControlNet 和 Lora 等精准控制工具。
如何避免 AI 生成图片的“塑料感”?
可以通过在 SD 中降低重绘幅度、引入真实摄影 Lora 模型,或者在后期通过 Photoshop 进行真实的胶片颗粒合成来打破 AI 的过度平滑感。
总结:构建“审美-指令-修正”的闭环能力
面对冲击,与其盲目精通所有工具,不如建立“审美-指令-修正”的闭环能力。核心竞争力不再是提示词的长短,而是定义视觉标准的能力。建议从建立个人风格的 Lora 模型开始,将真实的创作风格数字化,让 AI 成为风格的放大器。