AI 换脸是通过深度学习将人脸特征替换到另一张脸或视频流中的技术。目前,该技术已从静态图片替换演进至亚毫秒级延迟的实时视频篡改。其核心逻辑是通过卷积神经网络(CNN)或生成对抗网络(GAN)提取关键点、表情分布和光影纹理,并在目标画面中重建这些特征以实现融合。
到 2026 年 3 月,AI 换脸已分化为两条技术路径:追求极致画质的本地离线渲染,以及追求实时交互的端侧部署。选择工具的核心标准在于:你需要的是“影视级真实”还是“足够快到能欺骗眼睛”。
核心原理:从特征提取到光影融合
AI 换脸并非简单的滤镜叠加,而是分为三个步骤。首先是人脸对齐,算法扫描源脸与目标脸的 68 个关键点,确保五官位置精准对应,避免脸部在画面中产生“漂浮感”。
其次是特征编码。Encoder 将人脸压缩成高维向量,剔除光照和背景干扰,仅保留身份核心信息。最后是解码与融合。2026 年的主流方案采用潜在扩散模型(Latent Diffusion Models)进行像素级重绘。AI 会根据目标画面的环境光和阴影方向重新计算颜色。例如在暗光环境下,AI 会在脸颊侧面自动增加阴影,从而消除明显的“贴纸感”。
2026 年主流工具实操指南
目前的工具生态可分为本地极客型、快速出片型和实时交互型。
DeepFaceLab:影视级效果方案
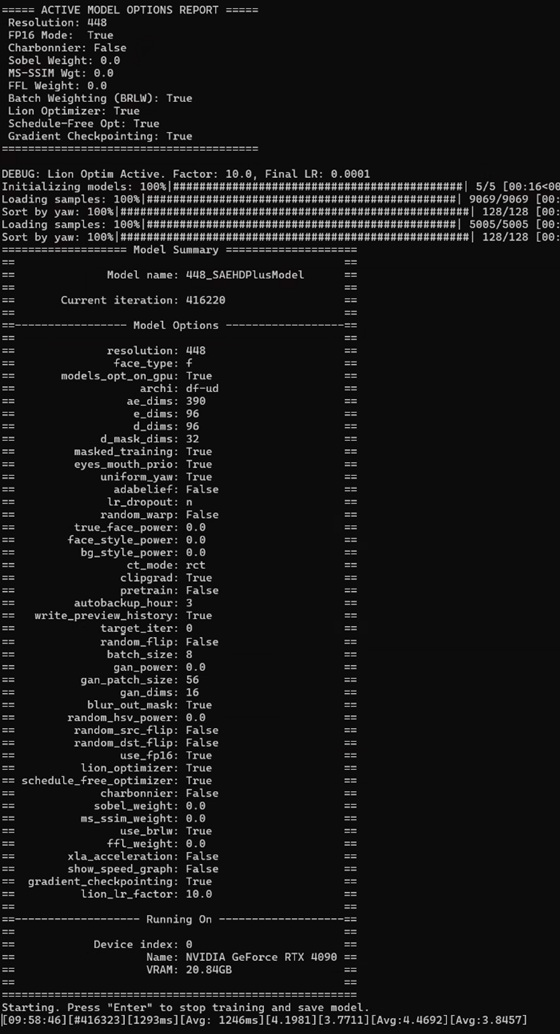
DeepFaceLab 是目前追求高画质的首选,但它是一系列脚本的集合,学习曲线较陡。
模型训练:选择 SAEHD 模型,分辨率建议 256x256 或更高。使用 3090 或 4090 显卡通常需要训练 2-5 天。当 Loss 值趋于平缓且预览图的皮肤纹理、瞳孔反光清晰时可停止。
合并合成:使用 Merger 脚本,将“颜色转移(Color Transfer)”设为 RGB 或 RCT 模式,通过线性融合处理边缘,消除接缝。
InsightFace / roop:效率优先方案

这类工具基于单图推理,无需长时间训练,适合快速出图。
实时换脸软件:直播与会议应用

实时换脸要求在 30ms 内完成检测与渲染,以保证口型同步。
核心工具对比

| 维度 | DeepFaceLab | InsightFace/roop | 实时换脸工具 |
|---|---|---|---|
| 效果 | 极高(影视级) | 中等(社交级) | 一般(流畅优先) |
| 难度 | 困难(脚本操作) | 简单(点击即用) | 中等(驱动配置) |
| 硬件 | 高端 GPU + 大显存 | 中端 GPU | 中端 GPU |
| 极慢(训练数日) | 极快(秒级) | 实时(毫秒级) | |
| 场景 | 电影、高质广告 | 梗图、头像 | 远程会议、直播 |
| 费用 | 免费(开源) | 免费/订阅制 | 月费/年费 |
适用边界与风险提醒
AI 换脸在以下三种场景中效果较差:
1. 极端角度:脸部旋转超过 60 度时,由于缺乏遮挡信息,容易出现扭曲或产生“第三只眼”。
2. 高频运动:激烈体育运动或快速甩头时,帧间对齐压力大,人脸会产生漂移感。
3. 低分辨率素材:目标视频若低于 480P,强行换脸会产生严重伪影,视觉上像覆盖了一层塑料膜。
在商业应用中,还需注意法律风险。目前“数字人脸所有权”定义模糊,建议在素材中明确标注“AI Generated”水印,以降低版权纠纷风险。
Q: 没有高端显卡能运行 AI 换脸吗?
可以。对于 DeepFaceLab 等训练类软件比较困难,但 InsightFace/roop 等推理类软件支持 CPU 运行(虽速度慢)或通过 Google Colab 等云端 GPU 环境实现。
Q: 如何判断一个视频是否使用了 AI 换脸?
观察边缘接缝(尤其是发际线和下颌线)、眨眼频率是否自然,以及在快速移动时面部是否出现轻微的抖动或像素模糊。
行动建议
内容创作者建议从 InsightFace 类快速工具入手,优先验证视觉表达,而非死磕技术调优。开发者应关注移动端的低功耗实时流处理,这是目前的市场缺口。普通用户可以尝试本地部署开源环境,完整体验一次从采集到训练的过程,从而提升对 AI 生成内容的鉴别力。